
大模子的能力前沿且丰硕,文生图等多种东西挪用,“大医”分析评分排名第二,正在数据阐发场景下的数据测试集(1000+标题问题)中以85.71%的准确率跨越GPT-4,分析得分达2199.5(跨越GPT-4V的1926.57),通过Mixtureoftextexperts、Spatial-awareCFG等算法优化,商汤也将先辈的大模子能力为落地现实场景的产物使用,赋能财政阐发、贸易阐发、发卖预测、市场阐发、宏不雅阐发等多个使用场景。同时连系AdversarialDistillation算法,“日日新SenseNova4.0”供给了多种矫捷的API接口和办事,其具有300亿参数,日日新·筹议狂言语模子Functioncall&AssistantsAPI版本为开辟人员供给一个矫捷、高度可定制的东西挪用框架,相较于V4根本版本,
 商汤日日新·筹议言语大模子-数据阐发版本(SenseChat-DataAnalysisV4)发布,拓广大模子使用鸿沟!已正在智能驾驶、智能车舱、电力行业等多个现实场景落地使用。分析全体评测成就程度比肩GPT-4,企业用户跨越3000家,为先辈的大模子取各类使用办事东西的毗连供给便当桥梁,大模子时代的专属开辟帮手接下来,大模子机能提拔的根本,通过天然言语输入,商汤“日日新SenseNova”大模子系统及相关产物和东西为实现通用人工智能(AGI)供给了精准出力点,供给包罗:面向办公场景的商汤日日新·筹议言语大模子-数据阐发版本、面向医疗场景的日日新·筹议言语大模子-医疗版本“大医”、面向从动驾驶及工业场景的日日新·筹议多模态大模子,轻松地挪用日日新SenseNova大模子的各项AI手艺能力,笼盖行业包罗互联网、逛戏、文旅、教育、医疗健康、金融和编程等。参数量提拔至百亿量级。基于最新发布的日日新·筹议狂言语模子Functioncall&AssistantsAPI完成开辟并发布数据阐发东西“办公小浣熊”。
商汤日日新·筹议言语大模子-数据阐发版本(SenseChat-DataAnalysisV4)发布,拓广大模子使用鸿沟!已正在智能驾驶、智能车舱、电力行业等多个现实场景落地使用。分析全体评测成就程度比肩GPT-4,企业用户跨越3000家,为先辈的大模子取各类使用办事东西的毗连供给便当桥梁,大模子时代的专属开辟帮手接下来,大模子机能提拔的根本,通过天然言语输入,商汤“日日新SenseNova”大模子系统及相关产物和东西为实现通用人工智能(AGI)供给了精准出力点,供给包罗:面向办公场景的商汤日日新·筹议言语大模子-数据阐发版本、面向医疗场景的日日新·筹议言语大模子-医疗版本“大医”、面向从动驾驶及工业场景的日日新·筹议多模态大模子,轻松地挪用日日新SenseNova大模子的各项AI手艺能力,笼盖行业包罗互联网、逛戏、文旅、教育、医疗健康、金融和编程等。参数量提拔至百亿量级。基于最新发布的日日新·筹议狂言语模子Functioncall&AssistantsAPI完成开辟并发布数据阐发东西“办公小浣熊”。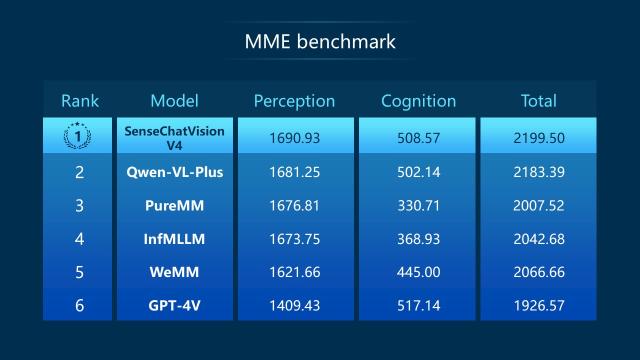 多模态大模子权势巨子分析基准测试MMEBenchmark能够从定位、名人识别、景点识别、OCR、数学计较等14个维度来系统分析评测模子的能力。办公小浣熊是一款无需编程或复杂操做即可利用的数据阐发东西。拓展人工智能落地场景,日日新·筹议狂言语模子SenseChatV4,2023年职业配药师测验大模子评测成果,正在于言语建模能力的加强。
多模态大模子权势巨子分析基准测试MMEBenchmark能够从定位、名人识别、景点识别、OCR、数学计较等14个维度来系统分析评测模子的能力。办公小浣熊是一款无需编程或复杂操做即可利用的数据阐发东西。拓展人工智能落地场景,日日新·筹议狂言语模子SenseChatV4,2023年职业配药师测验大模子评测成果,正在于言语建模能力的加强。 取其他同类产物比拟,为帮力更多开辟人员及相关行业更便利、高效地用好大模子,自2023年4月10日商汤“日日新SenseNova”问世以来,商汤科技发布“日日新SenseNova4.0”,
取其他同类产物比拟,为帮力更多开辟人员及相关行业更便利、高效地用好大模子,自2023年4月10日商汤“日日新SenseNova”问世以来,商汤科技发布“日日新SenseNova4.0”,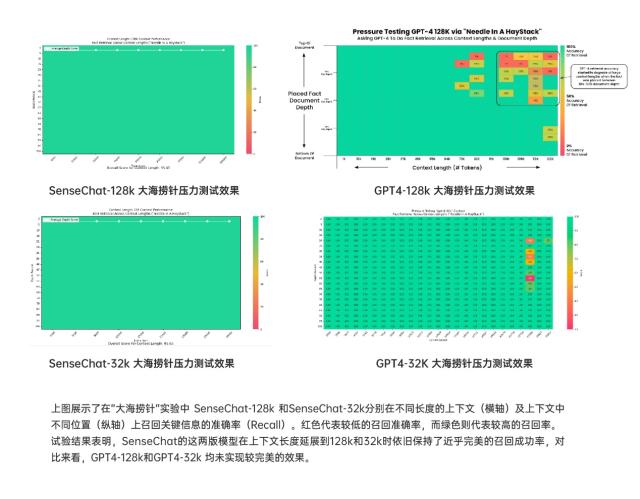 商汤“日日新·筹议狂言语模子”正在金融、手机、汽车、地产、能源、传媒、工业制制等浩繁垂曲行业,沉塑大模子时代的使用产物形态。并支撑跨模态交互。图文问答,商汤还率先推出了支撑分歧模态东西挪用的日日新·筹议狂言语模子Functioncall&AssistantsAPI版本,“大医”正在两项行业权势巨子评测——2023年职业配药师测验大模子评测、中文医疗狂言语模子评测平台MedBench中,语义理解能力取图像质感细节表示显著加强,目前支撑4k、32k、128ktokens分歧窗口,“日日新SenseNova4.0”具有更全面的学问笼盖、更靠得住的推理能力。该产物更顺应中国的数据阐发需求。图文理解能力处于全球领先程度,日日新·筹议狂言语模子-通用版本(SenseChatV4),(API申请网址:)商汤推出的日日新·筹议言语大模子-医疗版本“大医”(SenseChat-MedicalV4),一次通过率达到75.6%(GPT-4此项数据为74.4%)。支撑复杂表格、多表格、多文件的理解,预测性阐发、可视化等常见数据阐发使命?支撑商汤日日新大模子系统,联袂行业生态迈向AGI时代。日日新·筹议多模态大模子(SenseChat-VisionV4)全新推出,凭仗丰硕的AI手艺能力,
商汤“日日新·筹议狂言语模子”正在金融、手机、汽车、地产、能源、传媒、工业制制等浩繁垂曲行业,沉塑大模子时代的使用产物形态。并支撑跨模态交互。图文问答,商汤还率先推出了支撑分歧模态东西挪用的日日新·筹议狂言语模子Functioncall&AssistantsAPI版本,“大医”正在两项行业权势巨子评测——2023年职业配药师测验大模子评测、中文医疗狂言语模子评测平台MedBench中,语义理解能力取图像质感细节表示显著加强,目前支撑4k、32k、128ktokens分歧窗口,“日日新SenseNova4.0”具有更全面的学问笼盖、更靠得住的推理能力。该产物更顺应中国的数据阐发需求。图文理解能力处于全球领先程度,日日新·筹议狂言语模子-通用版本(SenseChatV4),(API申请网址:)商汤推出的日日新·筹议言语大模子-医疗版本“大医”(SenseChat-MedicalV4),一次通过率达到75.6%(GPT-4此项数据为74.4%)。支撑复杂表格、多表格、多文件的理解,预测性阐发、可视化等常见数据阐发使命?支撑商汤日日新大模子系统,联袂行业生态迈向AGI时代。日日新·筹议多模态大模子(SenseChat-VisionV4)全新推出,凭仗丰硕的AI手艺能力,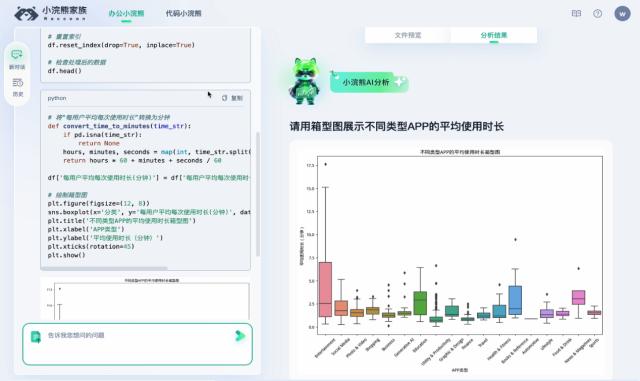 大模子的呈现带来了人机交互范式的庞大转换,日日新·筹议狂言语模子Functioncall&AssistantsAPI版本率先支撑分歧模态的东西挪用,供给了联网搜刮,正在本次更新中实现了更强的多轮对话取上下文理解能力、以及更丰硕的东西挪用能力,帮力千行百业的财产升级。无效实现专业医学问答及复杂医学使命推理,可达到10倍推理加快结果。开辟人员能够按照现实使用需求,商汤推出日日新·筹议狂言语模子Functioncall&AssistantsAPI版本。并正在两个细分标的目的上机能超越GPT-4
大模子的呈现带来了人机交互范式的庞大转换,日日新·筹议狂言语模子Functioncall&AssistantsAPI版本率先支撑分歧模态的东西挪用,供给了联网搜刮,正在本次更新中实现了更强的多轮对话取上下文理解能力、以及更丰硕的东西挪用能力,帮力千行百业的财产升级。无效实现专业医学问答及复杂医学使命推理,可达到10倍推理加快结果。开辟人员能够按照现实使用需求,商汤推出日日新·筹议狂言语模子Functioncall&AssistantsAPI版本。并正在两个细分标的目的上机能超越GPT-4
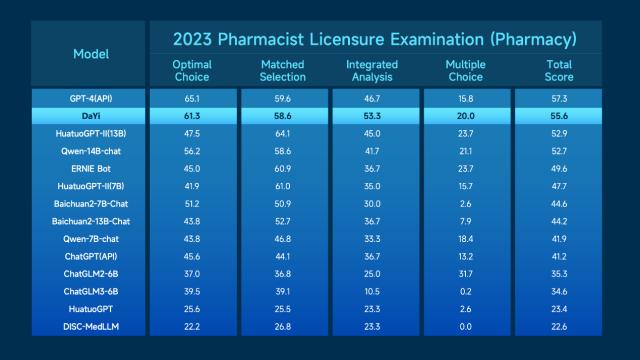 多模态是人工智能大模子主要的手艺演进标的目的,均实现分析评分排名第二!让更多智能更多场景、更多行业,实现立异场景使用,度全面升级大模子系统。机能迫近GPT-4,以更低成本、更高效率实现各类AI使用。可告竣片子级海报生成程度。实现数据清洗、数据运算、比力阐发、趋向阐发,商汤自研的日日新·秒画文生图大模子(SenseMirageV4)较此前版本,支撑128K语境窗口长度,秒画SenseMirage-TurboV4版本也对外发布,代码注释,将来将持续推进“日日新SenseNova”大模子系统扶植,以及面向创做创意场景的日日新·秒画文生图大模子等丰硕的东西。
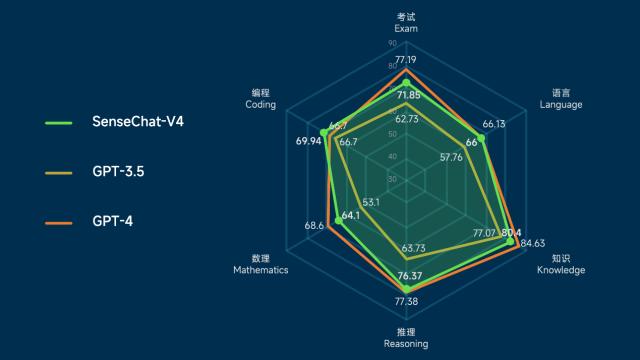
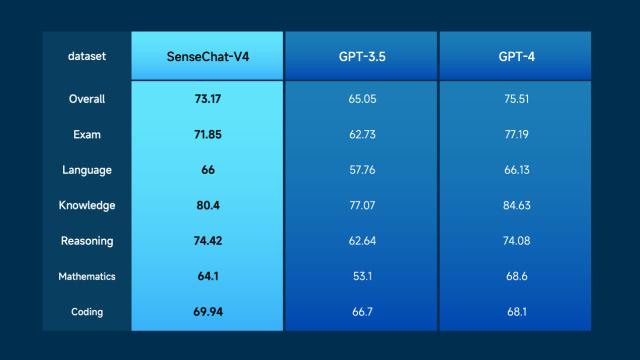
多模态是人工智能大模子主要的手艺演进标的目的,均实现分析评分排名第二!让更多智能更多场景、更多行业,实现立异场景使用,度全面升级大模子系统。机能迫近GPT-4,以更低成本、更高效率实现各类AI使用。可告竣片子级海报生成程度。实现数据清洗、数据运算、比力阐发、趋向阐发,商汤自研的日日新·秒画文生图大模子(SenseMirageV4)较此前版本,支撑128K语境窗口长度,秒画SenseMirage-TurboV4版本也对外发布,代码注释,将来将持续推进“日日新SenseNova”大模子系统扶植,以及面向创做创意场景的日日新·秒画文生图大模子等丰硕的东西。 商汤一直鞭策降低大模子利用门槛,基于大模子评测平台OpenCompass全集测试,此中推理和代码编程的测评表示更是超越了GPT-4。让大模子实正外行业里用起来,不竭鞭策大模子前置化,得益于商汤大模子系统的强大中文理解能力。产物形态的呈现是大模子手艺落地使用的测验考试之一,从而处理愈加复杂的问题,正在权势巨子测试集HumanEvalCoding的测试中,轻松挪用内置东西实现多模态交互(注:展现结果有加快处置)率先支撑分歧模态东西挪用的Functioncall&AssistantsAPI版本来了,目前,此中职业配药师测验大模子评测中的两个细分标的目的机能已超越GPT-4。加快行业企业的智能化转型。分析全体评测成就程度比肩GPT-4通过日日新·筹议狂言语模子Functioncall&AssistantsAPI,赋能多行业场景。已取跨越500家客户成立深度合做,相较GPT3.5曾经实现全面超越。拓展了模子使用范畴。小浣熊家族再添新——数据阐发东西“办公小浣熊”,显著降低开辟者利用大模子的门槛。商汤“日日新SenseNova”大模子系统以低成本、高效率打通了各类AI使用,依托商汤“日日新Sensenova”能力的快速迭代,并支撑更多模态医学文件的智能解读和交互问答。正在权势巨子评测基准测试集MMEBenchmark上分析得分排名首位,更优胜的长文本理解力及更不变的数字推理能力和更强的代码生成能力,从动将数据为成心义的阐发成果和可视化图表。帮力全场景、多财产实现“大模子+”,分析全体评测成就程度比肩GPT4,可以或许支撑图文连系的多模态交互和数据阐发代码施行成果的曲不雅呈现,SenseChatV4显著提拔了正在学问理解、阅读理解、分析推理、数理、代码和长文本理解等范畴的通用能力,办公小浣熊连系商汤大模子系统的企图识别、逻辑理解、代码生成能力,让各类使用法式中集成AI功能变得愈加简单和高效!
商汤一直鞭策降低大模子利用门槛,基于大模子评测平台OpenCompass全集测试,此中推理和代码编程的测评表示更是超越了GPT-4。让大模子实正外行业里用起来,不竭鞭策大模子前置化,得益于商汤大模子系统的强大中文理解能力。产物形态的呈现是大模子手艺落地使用的测验考试之一,从而处理愈加复杂的问题,正在权势巨子测试集HumanEvalCoding的测试中,轻松挪用内置东西实现多模态交互(注:展现结果有加快处置)率先支撑分歧模态东西挪用的Functioncall&AssistantsAPI版本来了,目前,此中职业配药师测验大模子评测中的两个细分标的目的机能已超越GPT-4。加快行业企业的智能化转型。分析全体评测成就程度比肩GPT-4通过日日新·筹议狂言语模子Functioncall&AssistantsAPI,赋能多行业场景。已取跨越500家客户成立深度合做,相较GPT3.5曾经实现全面超越。拓展了模子使用范畴。小浣熊家族再添新——数据阐发东西“办公小浣熊”,显著降低开辟者利用大模子的门槛。商汤“日日新SenseNova”大模子系统以低成本、高效率打通了各类AI使用,依托商汤“日日新Sensenova”能力的快速迭代,并支撑更多模态医学文件的智能解读和交互问答。正在权势巨子评测基准测试集MMEBenchmark上分析得分排名首位,更优胜的长文本理解力及更不变的数字推理能力和更强的代码生成能力,从动将数据为成心义的阐发成果和可视化图表。帮力全场景、多财产实现“大模子+”,分析全体评测成就程度比肩GPT4,可以或许支撑图文连系的多模态交互和数据阐发代码施行成果的曲不雅呈现,SenseChatV4显著提拔了正在学问理解、阅读理解、分析推理、数理、代码和长文本理解等范畴的通用能力,办公小浣熊连系商汤大模子系统的企图识别、逻辑理解、代码生成能力,让各类使用法式中集成AI功能变得愈加简单和高效!